
COCONUT - Chain of Continuous Thought

Rethinking Language Model Generation: Beyond Token-by-Token Processing
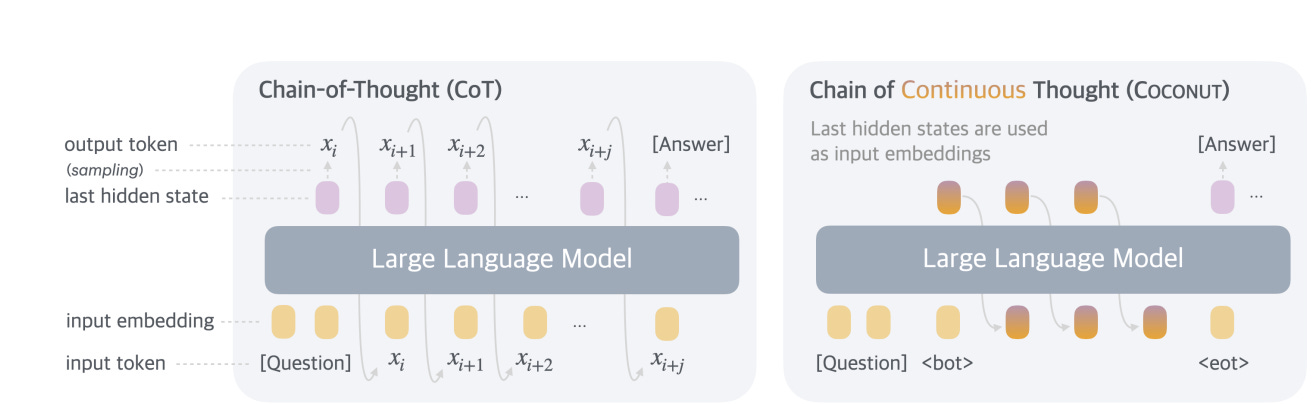
Understanding Traditional Autoregressive Generation
In traditional autoregressive language models like GPT (Generative Pre-trained Transformer), text generation follows a sequential, token-by-token process. When we provide a prompt to the model, it generates its response one token at a time. Here's how this process works:
1. The model receives an initial prompt
2. It generates a token based on the prompt
3. This new token is appended to the existing sequence
4. The expanded sequence becomes the new context for generating the next token
5. This process continues until the response is complete
The token selection typically involves sampling from a probability distribution, where tokens with higher probabilities are more likely to be chosen. While this approach has proven successful, it raises an interesting question: Does this step-by-step token generation truly reflect how reasoning works?
A New Perspective: Latent Reasoning
The Coconut paper by Meta proposes an alternative approach that challenges this token-by-token generation paradigm. Instead of immediately converting the model's internal state (logits) into discrete tokens, what if we kept this information within the model and allowed it to evolve?
The Proposed Mechanism
In this new approach:
1. Rather than sampling a token from the probability distribution at each step, the model's activations at step i are preserved in their raw form
2. These activations are fed back into the embedding layer directly, without being converted to discrete tokens
3. This process creates a continuous flow of latent information, allowing the model to "think" in a more fluid, abstract space
4. The model continues this internal reasoning process until it has completed its thought process
5. Only then is the final output converted into discrete tokens
This mechanism suggests that reasoning might be better represented as a continuous, latent process rather than a series of discrete token choices. The model can maintain and manipulate more nuanced, variable representations before committing to specific tokens.
Why This Matters
This alternative approach provides several interesting implications:
- It more closely aligns with human reasoning processes, where thoughts evolve continuously rather than in discrete steps
- It allows the model to maintain uncertainty and ambiguity during its reasoning process
- The final output benefits from a more holistic reasoning process rather than being constrained by early token commitments
Technical Implementation
The key technical insight that enables this approach lies in a crucial dimensional compatibility within transformer architectures. Here's how it works:
Dimensional Compatibility
The researchers leverage an important property of transformer models: the dimension of the final logit layer's hidden state matches the embedding dimension. This dimensional alignment is what makes the continuous latent processing possible.
For example, if you have a sequence of n tokens:
1. For the (n+1)th position, instead of selecting a discrete token, you can use the hidden state from the logit layer directly
2. Since this hidden state has the same dimensionality as the embedding space, it can be directly fed back into the sequence
3. This allows for another forward pass without requiring token discretization
The Process in Detail
Let's walk through this step-by-step:
1. Start with your initial sequence of n tokens
2. Perform a forward pass to get the (n+1)th position's hidden state
3. Because the hidden state dimension matches the embedding dimension, append it directly to the sequence
4. Perform another forward pass with this extended sequence
5. Repeat this process for subsequent positions
This creates a continuous flow where the model can propagate and refine its internal representations without being forced to commit to discrete tokens at each step. The model's "thinking" happens in this continuous embedding space, allowing for more nuanced reasoning before any discrete choices are made.
Advantages of This Approach
This implementation has several technical benefits:
- Maintains the full information content of the hidden states without loss from discretization
- Allows for smoother gradient flow during the reasoning process
- Enables the model to maintain uncertainty in its reasoning until necessary
- Potentially captures more complex dependencies between different parts of the generation process
Training the Model for Latent Thinking
Why Additional Training is Necessary
A natural question that might arise is: "Why can't we just use existing pre-trained models with this latent approach?" The answer lies in how language models are traditionally trained. During pre-training, models learn to predict the next token in a sequence using discrete tokens. However, the latent thinking approach requires the model to reason using continuous hidden states, which is a different mode of operation that needs to be explicitly trained.
Training Data Structure
The researchers use question-answer datasets that include chain-of-thought (CoT) steps. For example:
```
Question: What is the sum of 35 and 34?
Step 1: First, add 5 + 4 = 9
Step 2: Then, add 30 + 30 = 60
Step 3: Finally, 60 + 9 = 69
Answer: 69
```
The Training Curriculum
To train the model to switch between discrete and latent modes, the authors introduce special tokens: BOT (Beginning of Thought) and EOT (End of Thought). The training process involves multiple loops, replacing different portions of the chain-of-thought steps with these special tokens.
Training Loop Structure
For a chain-of-thought with n steps, the training involves n+1 loops:
0. Zeroth Loop
- Include BOT/EOT tokens along with all steps
- Calculate loss on all subsequent text
```
Question: What is the sum of 35 and 34?
[BOT][EOT]
Step 1: First, add 5 + 4 = 9
Step 2: Then, add 30 + 30 = 60
Step 3: Finally, 60 + 9 = 69
Answer: 69
```
1. First Loop
- Replace Step 1 with BOT/EOT
- Calculate loss on remaining steps (2, 3, ..., n) and answer
```
Question: What is the sum of 35 and 34?
[BOT][EOT]
Step 2: Then, add 30 + 30 = 60
Step 3: Finally, 60 + 9 = 69
Answer: 69
```
2. Second Loop
- Replace Steps 1 and 2 with BOT/EOT
- Calculate loss on remaining steps and answer
```
Question: What is the sum of 35 and 34?
[BOT][EOT]
Step 3: Finally, 60 + 9 = 69
Answer: 69
```
3. Third Loop
- Replace all steps with BOT/EOT
- Calculate loss only on the answer
```
Question: What is the sum of 35 and 34?
[BOT][EOT]
Answer: 69
```
Inference Process
During inference, when we want the model to use latent thinking:
1. We prompt the model with the question and a BOT token
2. The model switches to latent mode
3. We specify a fixed number of latent thinking steps (e.g., 3 loops)
4. After completing these steps, the model provides the final answer
This training curriculum enables the model to:
- Recognize when to switch to latent thinking mode (triggered by BOT token)
- Maintain coherent reasoning in the continuous space
- Generate appropriate final answers after latent thinking